Context Preservation is When The Moment Feels Right
Context of a photo is everything that tells you why the moment mattered.
Identity, context, and photographic aesthetics are the three core challenges of personalized visual generation. This blog series explores each in depth. Together, they define what it takes to make visual GenAI truly work for photography.
In our last “Phota of the Day,” we shared a photo of a genuine laugh. To the photographer and the people who were there, it wasn’t just about a photo with good composition and lighting. It was that night at the restaurant, under the string lights, with a dessert on the table. The photo captures a person, but what makes it alive is the context — everything around that person that tells you why the moment mattered.
The two layers of context.
Factual layer: who, where, and when. These are objective elements: people, places, time of day.
Narrative layer: why the photo was taken and what the photographer intended to capture. This layer defines why the photo matters and the story it tells.
Both layers are essential. The first keeps the image accurate; the second makes it meaningful. It’s like the difference between “a dinner” and “your birthday dinner”.
Capturing the second layer is what turns a good photo into a great story. It’s what Henri Cartier-Bresson called the decisive moment: when the breath hits the flame of the birthday candle and it flickers, or when someone looks back after saying goodbye.
LLMs and context understanding.
It can take years of experience for a photographer to recognize the kind of decisive moment that carries deeper meaning or visual balance.
But in everyday settings, most decisive moments are simpler and more universal. They follow social and physical patterns that language models already understand: when everyone in a group finally looks at the camera, when someone catches the bride’s bouquet, when the candle flame bends as a girl blows it out.
These are the moments people intuitively imagine for these events, but rarely capture perfectly. Nowadays, a language model can help surface and describe them because it understands context — the event (a birthday), the subject (the child), and the essence (the breath before the candles go out).
A photo is more than a thousand words.
Even though language models can describe a decisive moment, they still miss countless details: what the cake looks like, how the room is lit, the color of the candles, whether Happy Birthday was written in cream or chocolate. One could try to describe every part of the scene in words, but language quickly runs out of space for context. A photo, however, shows it all at once.
The context is often beyond a single image.
A single image is almost never enough to represent a full moment. We either snap multiple, or take a video to record everything.
Sometimes, it’s the lack of field of view to cover the entire scenery, like taking picture inside a cathedral where the ceiling is always out of frame.
Sometimes, it’s the moment that’s impossible to capture with a casual device, like the split second when someone opens a surprise gift.
Sometimes, it’s the moment we pictured in our mind as the perfect shot, but it never actually happened, like everyone mid-jump at once for a group photo that was always off.
Our photo album is filled with these small episodes of our lives, each of which could have become a great photo or a lovely story, but never quite did on its own.
When AI understands the context and can reimagine the scene, it starts to bridge that gap.
 Fig 1. After seeing the first two failed group shots and the full view of the chapel, the system understands the user’s intent and produces a photo that captures both the family and the chapel.
Fig 1. After seeing the first two failed group shots and the full view of the chapel, the system understands the user’s intent and produces a photo that captures both the family and the chapel.
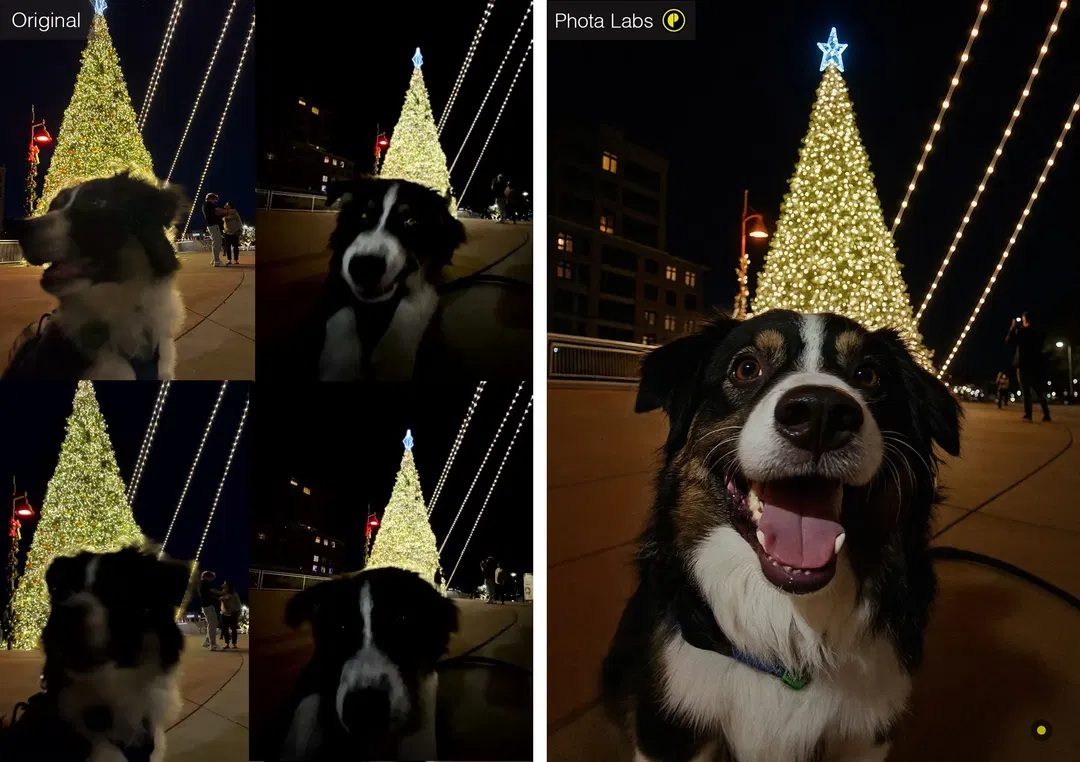 Fig 2. The event (a holiday scene), the subject (the dog), and the essence (the dog posing in front of the Christmas tree). By understanding these, the system captures a charming moment with our uncooperative subject.
Fig 2. The event (a holiday scene), the subject (the dog), and the essence (the dog posing in front of the Christmas tree). By understanding these, the system captures a charming moment with our uncooperative subject.
Sometimes, the human needs to be in the loop.
Not all context can be inferred from images alone. Sometimes it must come from the user: the parts of the story that never made it into the frame, or the personal sense of which moment truly matters.
A hiking video, for example, can have multiple “highlights”: the group reaching the summit, or the sweeping view from the top. Across a continuous stream of time and countless camera angles, the question becomes: which single moment best represents the experience?
The video already provides the event (a mountain hike on a clear day) and the subjects (the man and the dog). The essence, however, is subjective. It could be the group reaching the summit, or the panoramic view from the top.
 Fig 3. The original video frames record the panoramic landscape and the main subjects.
Fig 3. The original video frames record the panoramic landscape and the main subjects.
But once the system already understands the event context, expressing that preference becomes simple and intuitive. When the user tells the system, “prefer the background with the mountain”, that single cue guides it to select the right context from the original frames that matches their intent. Doesn’t that sound like how you would communicate with a photographer in real life?
 Fig 4. Left: system-generated result without guidance. Right: result after telling the system, “I prefer the background with the mountain.”
Fig 4. Left: system-generated result without guidance. Right: result after telling the system, “I prefer the background with the mountain.”
Evaluating context preservation through recognition and authenticity.
Just as the gold standard for evaluating identity preservation is self-judgment, assessing context preservation is also personal.
The first requirement is recognition: whether the image brings back a specific moment you have lived. When shown the photo, the question “Can you recall this moment?” should be an easy yes. This aligns with the factual layer of the context.
The higher requirement is authenticity, meaning the image captures the moment you hoped to catch and conveys the genuine emotion you felt at the time. Authenticity doesn’t always mean showing what actually happened. A generated photo doesn’t have to be factual to feel real. What’s more important is to align it with what could have happened based on the memory.
This reflects the narrative layer of context. In the hiking example above, although the combined moment didn’t actually occur, it genuinely captures both the breathtaking view and the subjects’ mix of joy and exhaustion after reaching the top.
At Phota Labs, we optimize for context completeness.
The more context we understand, the more we can inject into generation to make it feel authentic. That’s why, at Phota Labs, we believe truly personalized generation, the kind that feels real, depends on making context as complete as possible.
We use cameras to capture photos that become the most important source of context. But there’s also the question of how much information a single capture can hold. Modern imaging systems already move in this direction: multi-camera arrays infer depth, ultra-wide lenses expand spatial field of view, and sensors like polarization record how light interacts with materials, enabling more faithful lighting and texture.
We imagine a future where a camera doesn’t just optimize for image quality, but for the completeness of context, capturing not only what the world looks like, but what it is.
The future of photography is not just seeing better, but understanding better.
Phota of the day
There are moments where nothing is set up, and everything but the feeling goes wrong: an awkward angle, bad lighting, blurry faces, distracting window reflection, etc. Any existing editing tool/model may have declared this photo as “unfixable”.
But when a moment can be reimagined from the ground up, guided by real photography principles, the moment can be rediscovered.
 Before
Before  After
After