Generation Is the New Auto in Photography
GenAI elevates photography aesthetics and unlocks a truly intelligent Auto mode.
Identity, context, and photographic aesthetics are the three core challenges of personalized visual generation. This blog series explores each in depth. Together, they define what it takes to make visual GenAI truly work for photography.
I would have called this photo un-fixable. It’s the kind of shot you keep on your camera roll because the moment matters, but you never share it because you know there’s no saving it. There’s no software today that can make this image truly shareable.
 Fig 1. The kind of photo you keep but never share: a meaningful moment, but dark, blurry, and filled with distraction like clutter and window reflection.
Fig 1. The kind of photo you keep but never share: a meaningful moment, but dark, blurry, and filled with distraction like clutter and window reflection.
But we can articulate exactly why it’s a bad photo: faces that are dark and blurry, the awkward selfie angle, distracting window reflections, heavy noise in the shadows, and so on.
If a real photographer were on set, could they have avoided all of these issues while keeping the moment intact? Absolutely. They’d probably:
- Use a polarizing filter to cut reflections.
- Use fill light to balance the back-lit exposure on faces.
- Adjust the table items to reduce clutter in the foreground.
- Step back to avoid the tight selfie composition.
Does a VLM understand all this? Yes! The list above was generated by one. These models already understand photography principles, aesthetics, and what makes an image “good.”
And as understanding and generation get unified with large generative models, a regeneration can correct all of these issues holistically, because the model inherently knows what a “good photo” looks like.
 Fig 2. Regenerated with a single step: composition, lighting, and clarity corrected holistically.
Fig 2. Regenerated with a single step: composition, lighting, and clarity corrected holistically.
Before: Fixing a Photo Step by Isolated Step.
Before GenAI, photo editing workflows were fragmented into a chain of tools. Some steps are concrete and quantifiable, others are hard to define or encode.
Using the example above:
Quantifiable Corrections: tasks that have defined parameters, even if they’re technically difficult:
- Denoising: Guess the noise level and remove it without smoothing out detail.
- Deblurring: Infer local blur kernels (i.e., how the photo got blurry) and undo it.
- Reflection removal: Detect the reflection region, then split each pixel into “transmission vs reflection,” a difficult but well-defined problem.
Qualitative Adjustments: tasks that rely on aesthetic judgment rather than fixed rules:
- Relighting: Fix the back-lit face, but how? “More diffuse, less harsh” is still not a precise instruction a system can reliably act on.
- Composition: The photo does have a too tight composition due to the selfie perspective, but what transformation should fix it?
Each step is hard on its own. The order also matters. And any artifact in one step compounds into the next. It’s a brittle pipeline where error accumulation is almost unavoidable.
Now: Start From Intent.
We see a future where people won’t edit photos by thinking in terms of technical operations. No one will say, “I want to estimate the blur kernel” or “separate the reflection from the transmission layer.” They’ll simply want the photo to look the way they remember it.
Instead of performing a handful of small edits with a procedural mindset, we can now solve the entire problem in a single conceptual step:
Understand the scene → understand the intent → regenerate the photo as it should have been.
A strong generative model implicitly gets the composition, lighting, geometry and “decisive moment” right because it learns these principles directly from the world.
Solely relying on a large, generic generation model to fulfill the user’s intent isn’t enough. It may produce a “better photo”, but it won’t preserve the exact moment — the real people, the expressions, the scene, and the event that mattered in the first place. That gap between improving a photo and preserving the moment is exactly the challenge we chose to solve. We’ve written about identity and context preservation in more depth.
Before Taste, There’s a Shared Sense of What Makes a Photo Better
How do we know what’s good? Especially when aesthetics is so often labeled as subjective?
In practice, aesthetics has both an objective and a subjective component. The objective side is what we learn in Photography 101: composition fundamentals, lighting principles, and how a decisive moment is captured. These are learnable crafts. And most photos in our camera roll have plenty of room to improve on these basics.
Even though people have different style preferences, there is broad consensus around what counts as “better” in this objective sense, long before personal taste enters the conversation.
Every photo is meaningful to the person behind the camera. And we believe any photo can be elevated objectively, brought to a level where aesthetic preference, style, and personal taste actually start to matter.
 Fig 3. Left: the original photo. Right: three objectively improved renderings, each different, but all clearly better than the original.
Fig 3. Left: the original photo. Right: three objectively improved renderings, each different, but all clearly better than the original.
GenAI enables the objective elevation of photo quality.
Generation is the new auto. The best way to show this is through common scenarios where regeneration solves problems that traditional editing tools struggle with. For example:
Dynamic Range Limitations
A single exposure cannot simultaneously preserve detail in deep shadows and bright highlights; sensors saturate, and clipped regions contain no recoverable information. Multi-exposure HDR try to merge bracketed shots, but the alignment problem becomes ill-posed when there is motion, non-rigid deformation, or viewpoint changes.
Regeneration can reconstruct the photo as a unified moment.
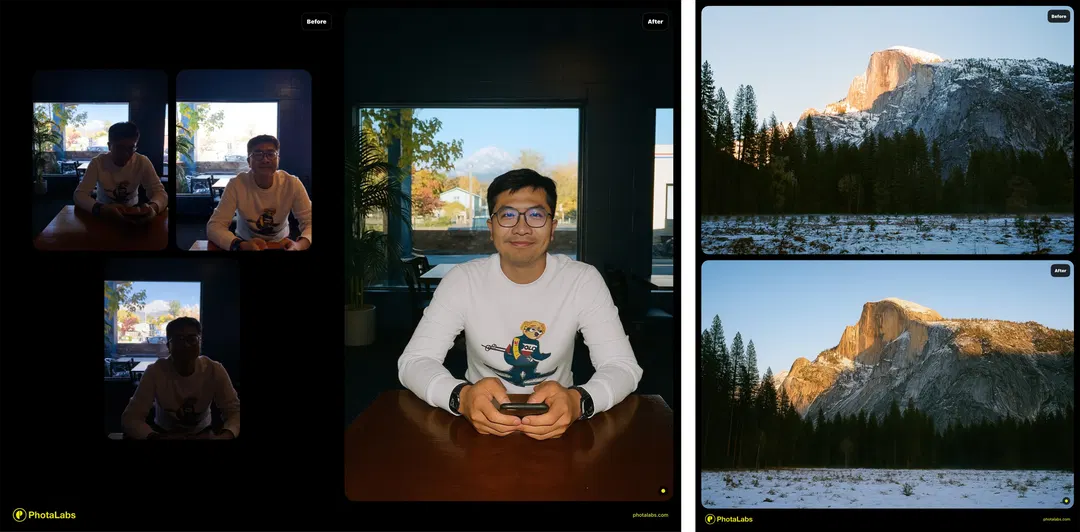 Fig 4. HDR: a single exposure blows out highlights or crushes shadows. Regeneration reconstructs the moment with balanced detail throughout the scene.
Fig 4. HDR: a single exposure blows out highlights or crushes shadows. Regeneration reconstructs the moment with balanced detail throughout the scene.
Low Light Constraints
In low light, the camera’s sensor amplifies noise, motion blur becomes more pronounced, and shadows lose detail. Regeneration addresses these constraints with a unified solution.
 Fig 5. Low-light scene: heavy noise, motion blur, and lost shadow detail. Regeneration resolves all in one coherent reconstruction.
Fig 5. Low-light scene: heavy noise, motion blur, and lost shadow detail. Regeneration resolves all in one coherent reconstruction.
Mis-focus
When the lens locks in on the wrong subject, there’s no way to “edit” the intended subject back with clarity, as the information simply isn’t there. Regeneration brought the moment back.

Composition and lighting
Even though these aspects involve aesthetic judgment, there is still broad agreement on what looks better in all of these examples.
 Fig 6. Even in composition and lighting, which involve aesthetic judgment, regeneration produces results that are objectively better.
Fig 6. Even in composition and lighting, which involve aesthetic judgment, regeneration produces results that are objectively better.
All examples in this article were generated with no sliders and no prompt on the user’s side. GenAI makes “auto mode” powerful in a way traditional editing never could. And that’s how this new form of editing — this new experience with photos — becomes accessible to anyone who simply enjoys taking and sharing them.
This post concludes our series on the three core challenges in personalized visual generation: identity, context, and photography aesthetics.
These three pillars depend on one another. A photography product isn’t meaningful if any one of them is missing.
Identity and context preservation ensure the image stays relevant — that the people, the place, and the moment remain true. They create the foundation for the next question: How do we make this photo better represent the memory?
Photography aesthetics answers that question. It elevates any photo to a shareable, compelling state, at a point where subjective taste and personal style can actually guide the final look.
That’s how we build a product that makes memories effortlessly beautiful.
Phota of the day
A beta user story: Sylvia, one of our angel investors, was giving a talk at an event. No photographer, just a friend taking a quick picture. But she needed a great shot for her social post. One click in Phota, and the casual snapshot became the photo she wished she had.
 Before
Before  After
After